Journal - Week 7
Journal - Week 7
Intro
Hi readers, and thanks again for using some of your valuable time to read my humble weekly post.
Today’s post will be very techy. I will put on my AWS cloud architect hat and explain our infrastructure tech stack, the reasons behind the decisions we took, and the trade-offs involved.
Let’s start.
The Infrastructure Tech Stack
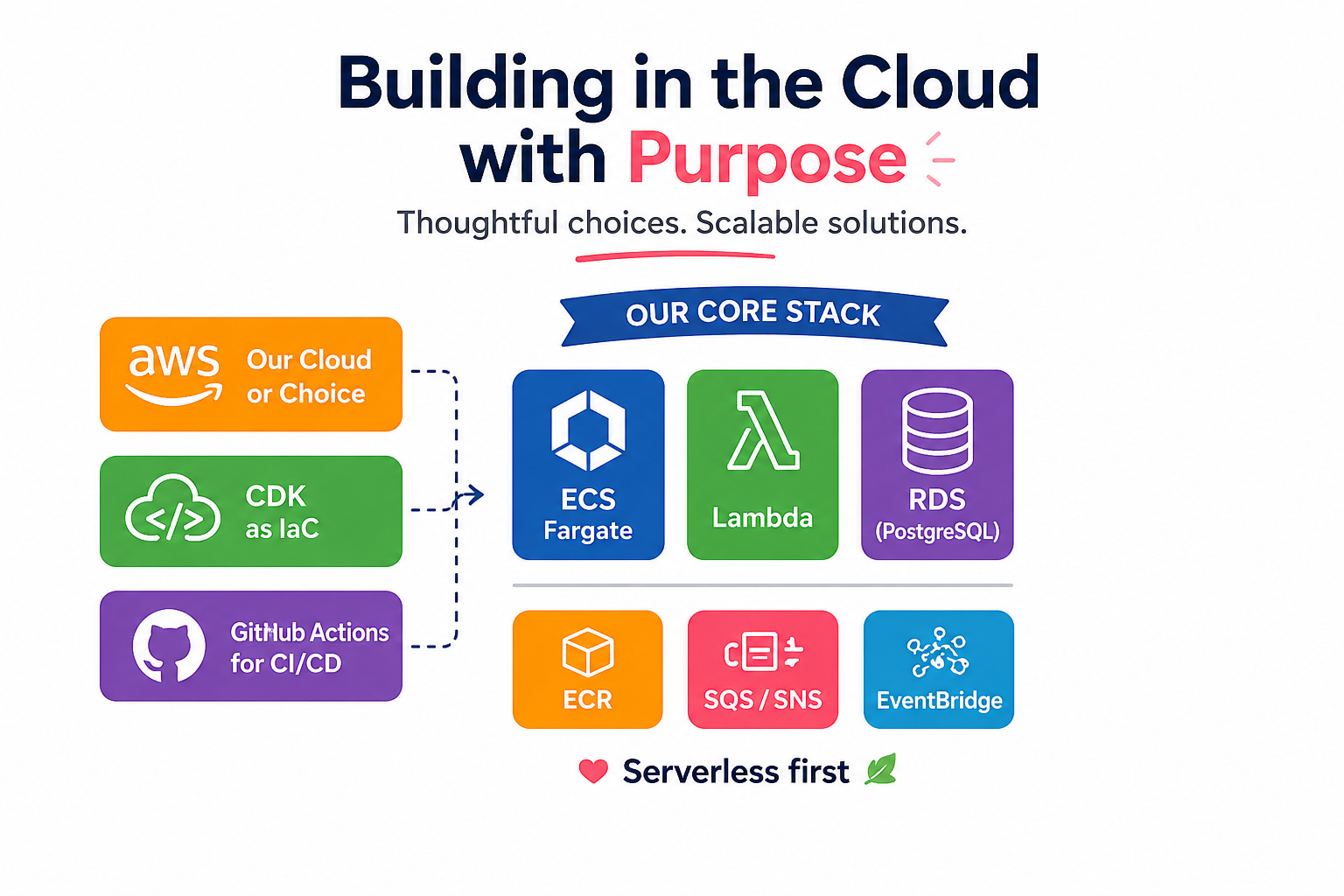
The Cloud
If we talk nowadays about a tech stack, the very first area to discuss is the cloud. As you know AWS, let’s first discuss why we chose it over other providers.
First of all, AWS is the leading cloud platform. It was the very first one to offer cloud hosting solutions as a service and has the largest market share. The main competitors, as you know, are Google with Google Cloud and Microsoft with Azure.
Honestly, all of them are very similar and provide all the architectural needs that a platform like the one we want to build requires, and choosing one or another is mostly a matter of taste.
The real comparison of options and trade-offs is with those kinds of PaaS providers that promise to abstract all the infrastructure headaches at a good cost.
Some of them that come to my mind are: Cloudflare, Railway, and Render.
We chose AWS as our cloud provider for three main reasons:
- we are already experienced with this cloud from other projects
- I know from other experiences that those easy-to-use cloud providers are fine for some standard products, but in the end, when you want to customize them to your real needs, you find yourself doing the same job (or even more) than expected in AWS
- Even though we chose AWS and built our own infrastructure “by hand,” we still opted for self-managed serverless solutions to outsource the maintenance of the services themselves (i.e. Fargate, Lambdas instead of our own EC2 instances)
- Price-wise, AWS is not cheap. From the business side, the command was to build a system that could eventually reach millions of people. AWS is a natural fit; it makes no sense to partner with a cloud provider that will not accompany us on our journey.
What about vendor lock-in, you may think? Yeah, it is true, but I am not worried about it. I am fine being locked into AWS. I will surely have worse partners on my journey.
Infrastructure as IaC
It is while building the infrastructure that we had our main new kid on the block: the new technology that we did not know very well and therefore required an effort (time) to get used to it.
I am talking about CDK for building our infrastructure. In other projects I have participated in, I was using Terraform as an IaC (Infrastructure as Code) partner.
It was great, but the natural step forward was using CDK. CDK “compiles” to CloudFormation, which is AWS’s proprietary equivalent of Terraform.
I am a huge, huge fan of IaC for building infrastructure. It prevents errors, is traceable and trackable since IaC changes are versioned, and is easy to read if you have been a developer.
If you read a bit about CDK, you will see that it allows you to describe infrastructure in several languages, with TypeScript being the native one. We chose it because most of the documentation is in this language, it is relatively easy to learn, and although it is not a super strict language aimed at building big enterprise codebases (yes guys, that is my opinion about TypeScript/JavaScript), for small script-like codebases such as the ones used to build IaC, it is flexible enough.
The CI/CD Layer
Here we had two main options.
Go with the proprietary AWS solutions for CI/CD or use the market standard nowadays. We chose the second one and built our workflows using GitHub Actions.
They are great, we already know them from other projects, they have hundreds of well-maintained plugins, and they integrate perfectly with our code repository of choice, GitHub.
There was no need to learn another technology, even if it is very similar to GitHub and could eventually integrate better with the whole AWS ecosystem.
The Resources
By resources, I mean choosing, from the myriad of resources that AWS offers, those that best fit our needs. I already gave you some clues about it.
We went for serverless resources like Fargate and Lambda, using ECS and ECR as container orchestrator and registry, and as much self-management as possible. When needed, we will use SQS, SNS, or EventBridge.
RDS will solve our persistence layer very well. For vector databases, for now we are fine using the pgvector add-on in Postgres, and if needed we would move to Amazon’s recommended solution.
Also, in case we need a more flexible persistence store, DynamoDB will be there to help us.
The Doubt
Every decision always comes with some open questions about whether we are choosing the right path. There is one resource that I am still not 100% convinced is the right one.
I am talking about ECS vs EKS.
As you know, both of them are container orchestrators, although ECS is AWS’s own solution and EKS is built on top of Kubernetes, the de facto standard.
I have worked with Kubernetes before and I know it well; I also liked it. I had never used ECS, so I was wondering what to do. I read that ECS is easier to use (let’s see, as always) and supports Fargate very well, and that drove the decision process.
Later on, I also read that EKS now integrates with Fargate quite well, so I wondered if the initial decision was wrong. Could it happen that AWS embraces EKS in the future and relegates ECS? We are just starting to set up the infrastructure, so maybe it is a good moment to have a second thought about it.
But after discussing it with the lead developer, we decided to keep using ECS. If we have to move to EKS in the future, using CDK as we are should make it feasible.
Conclusion
So this is the architecture we are using. We are quite happy with it, and I encourage you to tell me your opinions based on your experiences.
Until then, I wish you a great weekend.